
Sitemap
A list of all the posts and pages found on the site. For you robots out there, there is an XML version available for digesting as well.
Pages
Posts
Future Blog Post
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Blog Post number 4
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 2
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 1
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
about
portfolio
Portfolio item number 1
Short description of portfolio item number 1
Portfolio item number 2
Short description of portfolio item number 2
publications
Probably Approximate Shapley Fairness with Applications in Machine Learning
Published in AAAI 2023 (Oral), 2022

DETAIL: Task DEmonsTration Attribution for Interpretable In-context Learning
Published in NeurIPS 2024, 2024

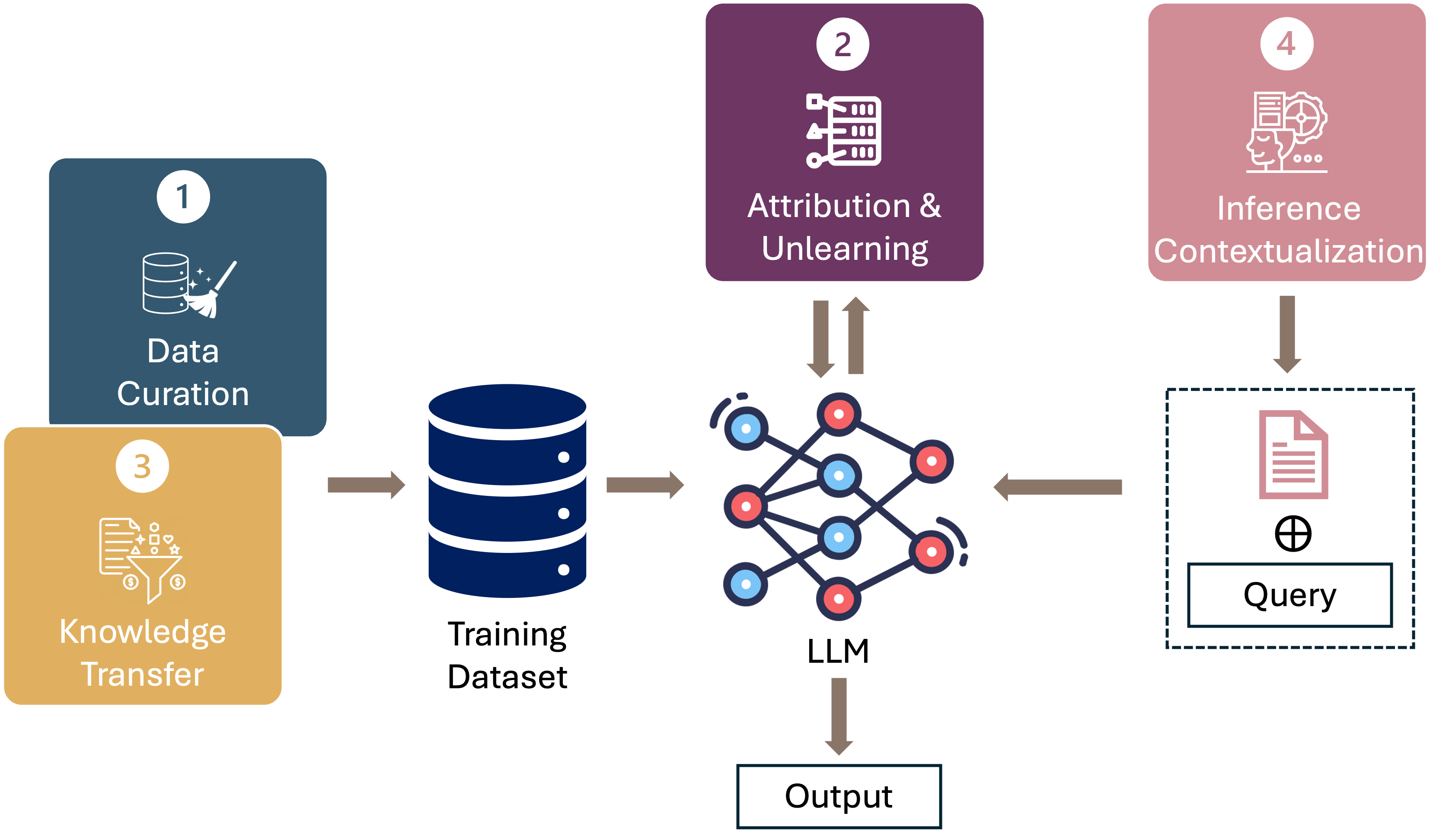
Data-Centric AI in the Age of Large Language Models
Published in EMNLP 2024 Findings, 2024
Data Value Estimation on Private Gradients
Published in arXiv, 2024
For gradient-based machine learning (ML) methods commonly adopted in practice such as stochastic gradient descent, the de facto differential privacy (DP) technique is perturbing the gradients with random Gaussian noise. Data valuation attributes the ML performance to the training data and is widely used in privacy-aware applications that require enforcing DP such as data pricing, collaborative ML, and federated learning (FL). Can existing data valuation methods still be used when DP is enforced via gradient perturbations? We show that the answer is no with the default approach of injecting i.i.d. random noise to the gradients because the estimation uncertainty of the data value estimation paradoxically linearly scales with more estimation budget, producing estimates almost like random guesses. To address this issue, we propose to instead inject carefully correlated noise to provably remove the linear scaling of estimation uncertainty w.r.t. the budget. We also empirically demonstrate that our method gives better data value estimates on various ML tasks and is applicable to use cases including dataset valuation and FL.
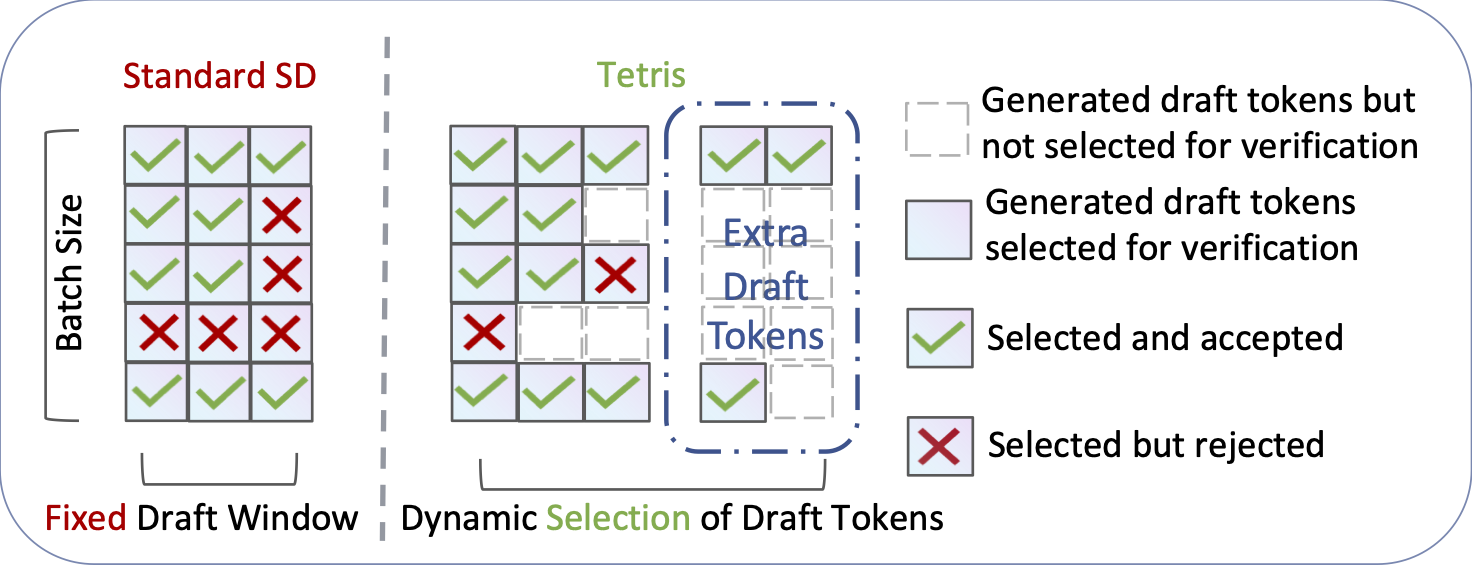
TETRIS: Optimal Draft Token Selection for Batch Speculative Decoding
Published in ACL 2025 Main, 2025
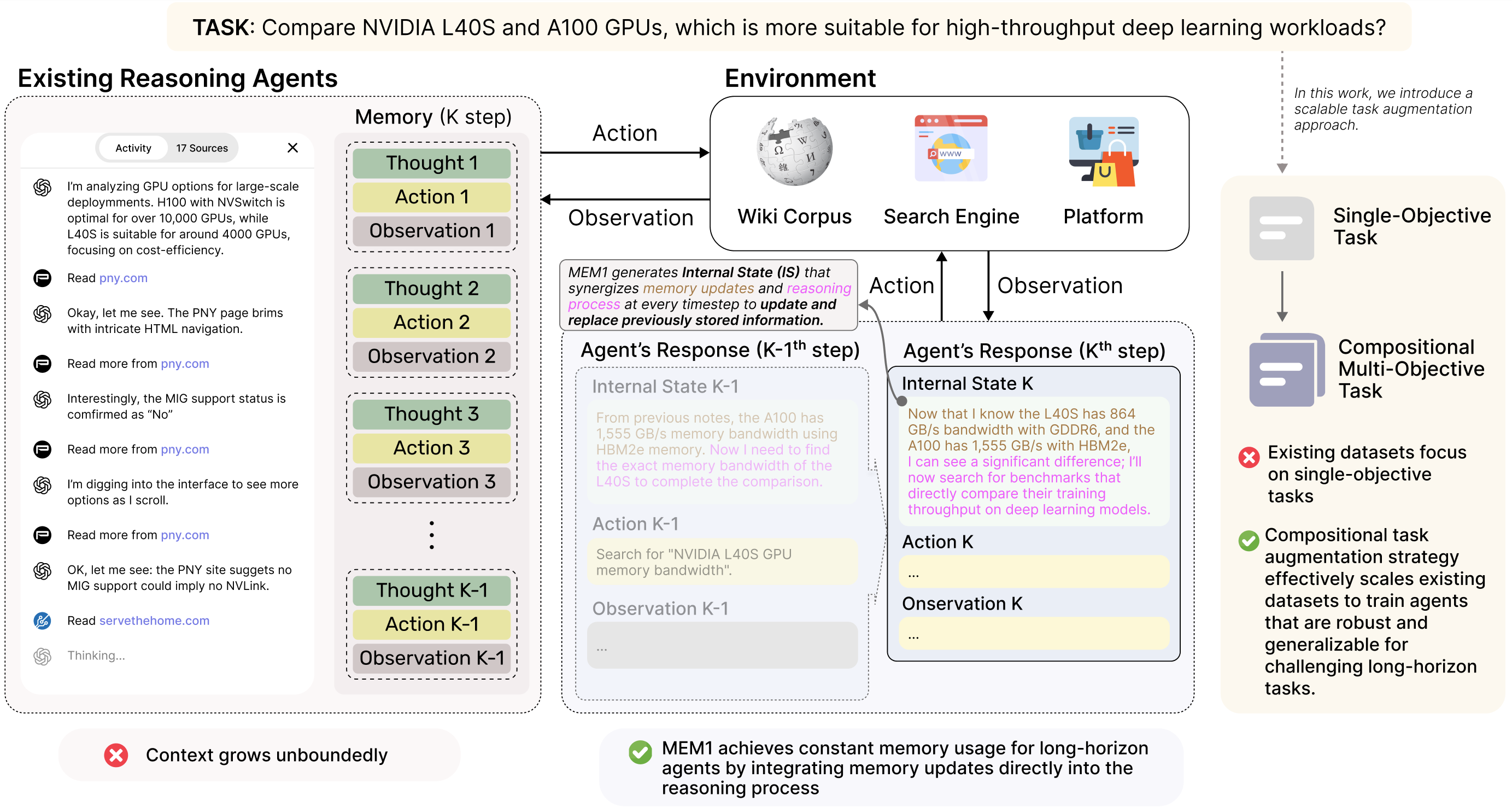
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Published in ICLR 2026, 2025
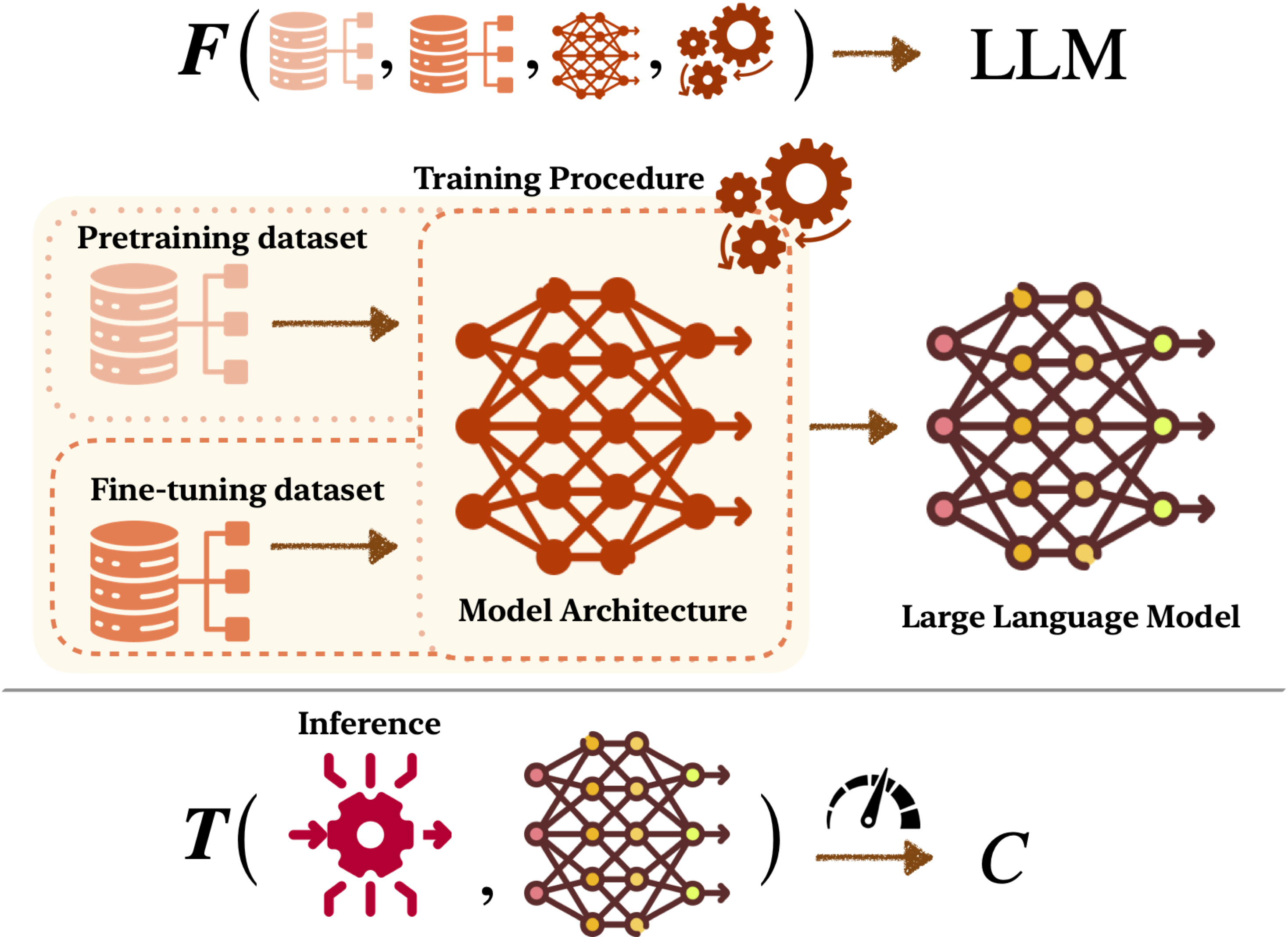
Uncover Scaling Laws for Large Language Models via Inverse Problems
Published in Under Review at ARR, 2025
talks
Talk 1 on Relevant Topic in Your Field
Published:
This is a description of your talk, which is a markdown file that can be all markdown-ified like any other post. Yay markdown!
Conference Proceeding talk 3 on Relevant Topic in Your Field
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
teaching
Teaching experience 1
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Teaching experience 2
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.